

作者: 夙愿学长
继 Vibe Coding 火了之后,现在又有一个概念火了,叫做 Context Engineering(上下文工程)。
上下文工程到底有多火?我给你举个例子:Shopify 现在招聘之前,第一件事不是写 JD,而是先评估这个岗位能不能用 AI + 上下文工程来解决。
如果可以,那就直接不招这个岗位了。
Karpathy 大神也跟贴表示:上下文工程是一门精心设计填充上下文窗口的艺术与科学。

那为什么 Context Engineering 会火?
因为大家逐渐发现一个事实:这一轮大模型的能力提升,已经接近瓶颈了。
指望「等一个更强的模型」来解决问题,越来越不现实。
所以现在的竞争,已经从「训练更好的模型」转向了「用好现有的模型」。
而「用好」的关键,就是上下文工程,你「喂」给模型什么信息,怎么组织这些信息,决定了模型输出质量的上限。
很多垂直领域的 Agent 产品,最大的护城河其实不是技术,而是上下文工程的能力,谁能让用户心甘情愿地交出更多高质量的上下文,并且处理得当,谁就更能留住用户。
但回到我们个人的日常使用中,情况却很糟糕。
你知道该怎么办:新开一个对话窗口。
但新窗口里,AI 又变回了“陌生人”。那些你在上个窗口里费了半天劲让它理解的背景、你的偏好、你的工作习惯,全没了。
这就是我们目前使用 AI 最大的瓶颈:
在一个窗口里,聊多了会乱;新开窗口,又会失忆。我们每天花大量时间在重复投喂背景信息,感觉像是在给 AI 打工。
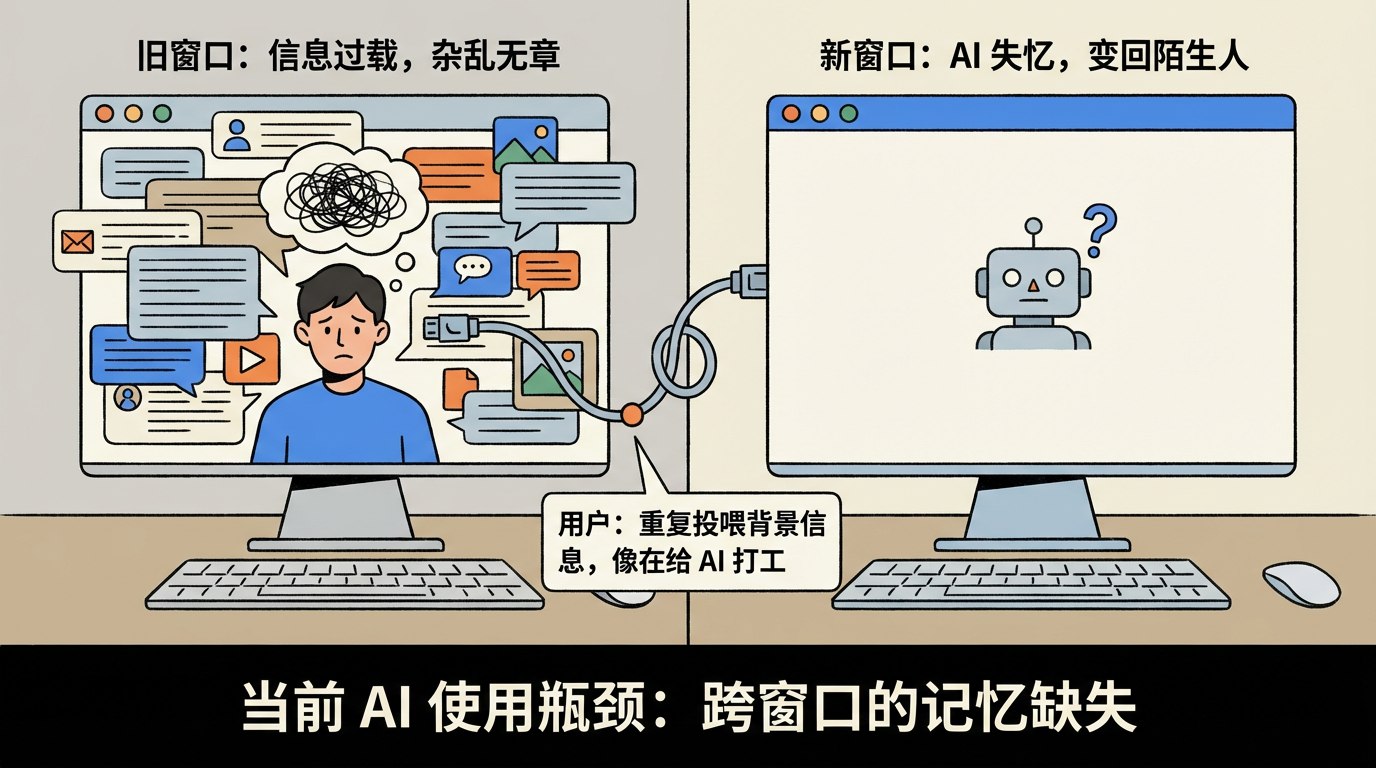
这篇文章,就是为了彻底解决这个问题。
这可不是一篇简单的技巧分享,而是一套完整的上下文工程管理工作流。
全文 16500 字,包含从基础的上下文管理(内循环),到高阶的知识库搭建(外循环),再到 Cherry Studio 的硬核配置教程。
学完这篇,我相信,你和 AI 的协作方式会发生质的变化。
一、上下文工程到底是什么
要弄懂上下文工程到底是什么?首先我们得明白什么是上下文。
当我们跟 AI 对话时,其实每个文字/符号、每一张图片、每一个文件,都在构建着一个「上下文」。
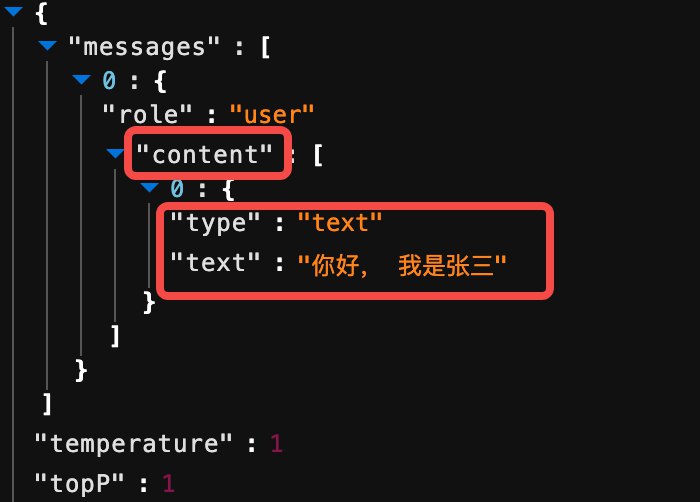
比如你在对话框里输入「你好,我是张三」、「你可以帮我写个文案吗?」,这些是上下文。
下面这张图展示了当我们跟模型对话,按下回车键之后到底发生了什么。
从这个模型调用参数的截图可以看到,「你好,我是张三」被包装成了 content(内容)的一部分,然后发送给大模型处理,最终得到大模型的回复。
接着你在对话框里粘贴了一张图片、上传了一个 PDF 文件,这也都是上下文。
你可能会有点疑惑,PDF 文件和图片这两个也不是文本(content)啊,为什么也是上下文呢?

© 版权声明
1. 如果您喜欢本站,点击这儿赞助下本站,感谢支持!
2. 本站永久网址:https://vip.zhendk.cn
3. 本站部分内容来源于网络,仅供大家学习与参考,如有侵权,请联系站长删除。
4. 本站一切资源不代表本站立场,不代表本站赞同其观点和对其真实性负责。
5. 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报。
6. 本站资源大多存储在云盘,如发现链接失效,请及时反馈,我们会第一时间更新。



